Bert-Vits2 2.3 Chinese Extra for local inference on Intel or Apple Silicon Mac
Introduction
Bert-VITS2 is an innovative text-to-speech synthesis project that combines the VITS2 backbone with a multilingual BERT model. This integration allows for enhanced speech synthesis capabilities, especially in multilingual contexts. The project is particularly noteworthy for its specialized version, “Extra: 中文特化版本,” tailored for Chinese language processing. This development represents a significant advancement in the field of speech synthesis, catering to diverse linguistic needs.
This tutorial will talk about how to running this project using the CPU under the Mac platform.
This tutorial is based on videos and practice from this site.
Below are the reference videos and documents:
-
How to elegantly create a Bert-VITS2 Dataset
-
[Bert-vits2] Cloud mirroring training tutorial with labeling ready to use
-
Don’t think about trainning on Mac yet, It’s good enough if they can preprocess and infer. Running LLM might be possible, but if anyone has successfully trained on a Mac (with MPS), please let me know.
-
This tutorial mainly talks about the inference process after training and downloading the model to the local machine. I have tested it, and it all works.
-
Training related information can be found in the reference videos above, which are very detailed. The dataset is the key, and patience is needed for training.
-
It’s even easier to use a one-click package, Bert-Vits2, which I’ve personally tested and it works quite well in Chinese.
Project link: https://github.com/fishaudio/Bert-VITS2
This tutorial is for communication and learning purposes only. Please do not use it for illegal, immoral, or unethical purposes.
Please ensure that you address any authorization issues related to the dataset on your own. You bear full responsibility for any problems arising from the usage of non-authorized datasets for training, as well as any resulting consequences. The repository and its maintainer, svc develop team, disclaim any association with or liability for the consequences.
It is strictly forbidden to use it for any political-related purposes.
Software requirements:
- Homebrew https://brew.sh/
- VScode (optional)
- Python3
I use Bert-Vits2 Extra Chinese specialization version, other versions pay attention to the training and inference of the version is the same https://github.com/fishaudio/Bert-VITS2/releases/tag/Extra
Bert-Vits2 Mac Inference
1. Create venv
Create a virtual environment
1 | python3 -m venv myenv #change 'myenv' to a different name |
2. Enter venv
1 | cd myenv |
1 | source bin/activate |
3. Download project
1 | https://github.com/fishaudio/BertVITS2/archive/refs/tags/Extra.zip |
Unzip it yourself after downloading
cd to the project directory
4. Install packages
1 | pip install -r requirements.txt |
1 | pip install torch torchvision torchaudio |
5. Launch WebUI
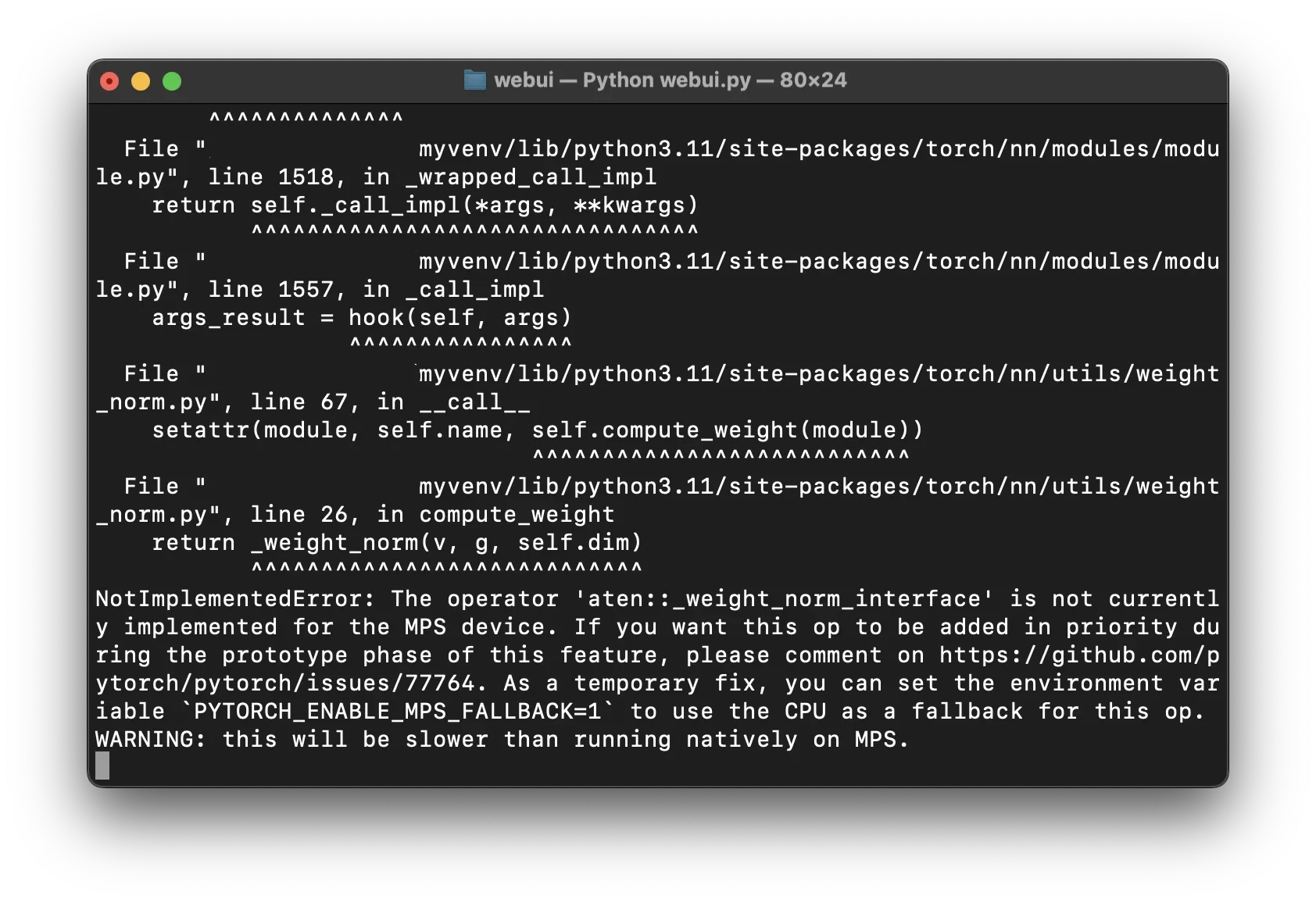
Launch WebUI to see the reported error
1 | python webui.py |
In my test it’s mostly less files and using CPU reasoning
6. Change config.yml
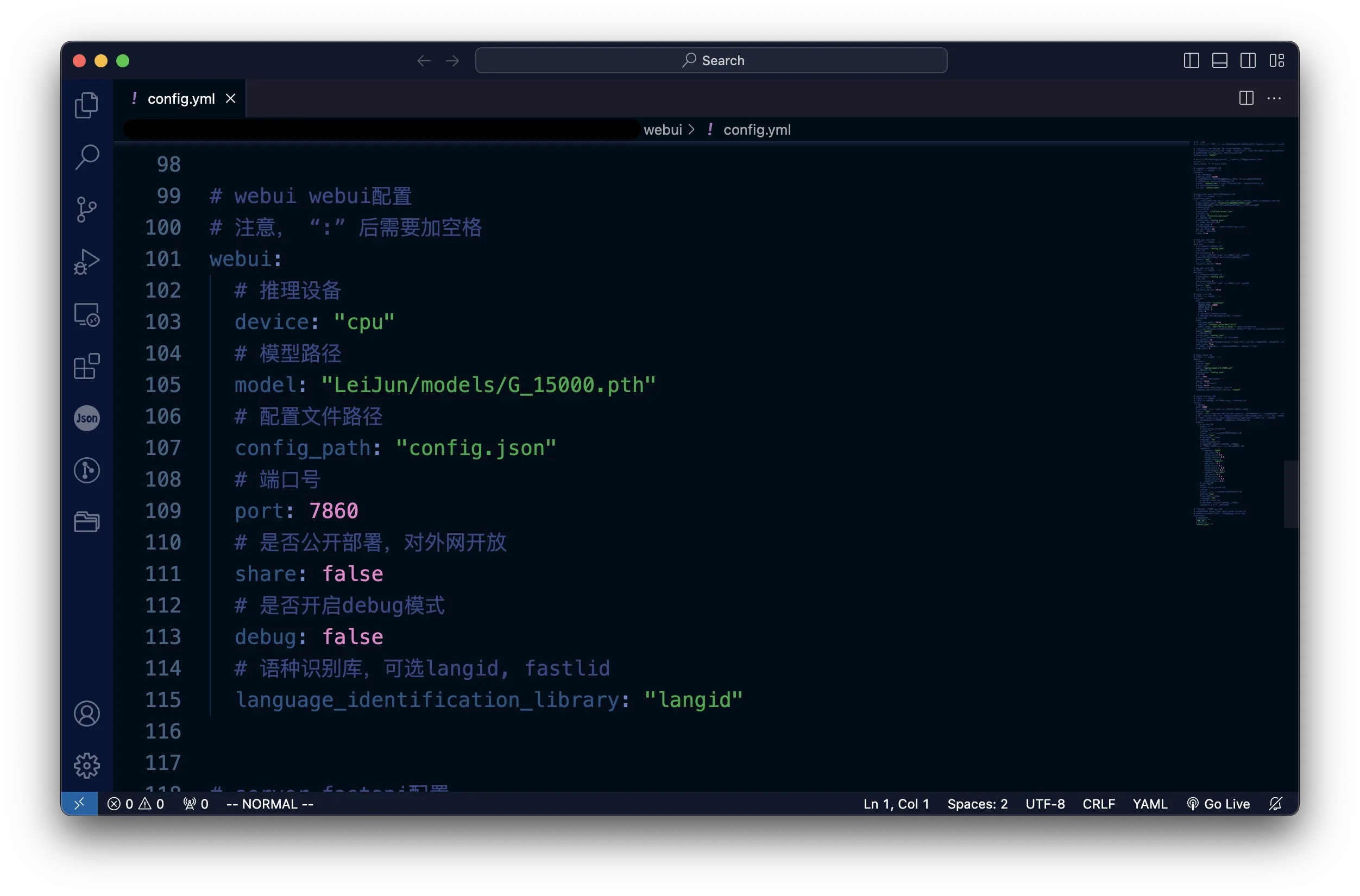
7. Change some other files
I’ll put the file I tested down on github for reference
https://github.com/One-CloseX/Bert-Vits2-Mac-Changed-File
The file was changed a few days ago. I don’t remember what exactly. If you can run it, don’t move it.
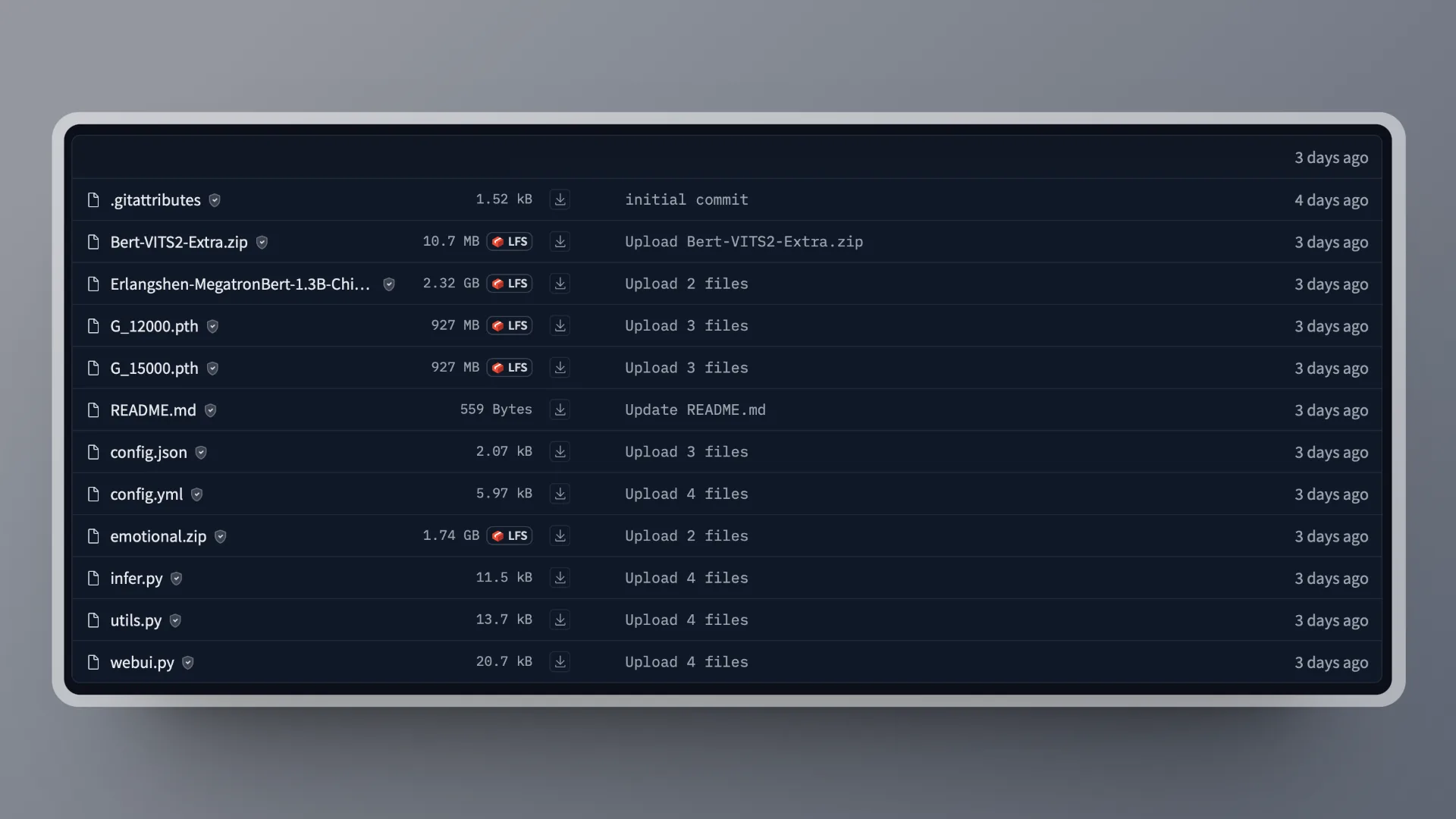
Replace the other files according to the error
Erlangshen-MegatronBert-1.3B-Chinese and Emotion folders, unzip them first.
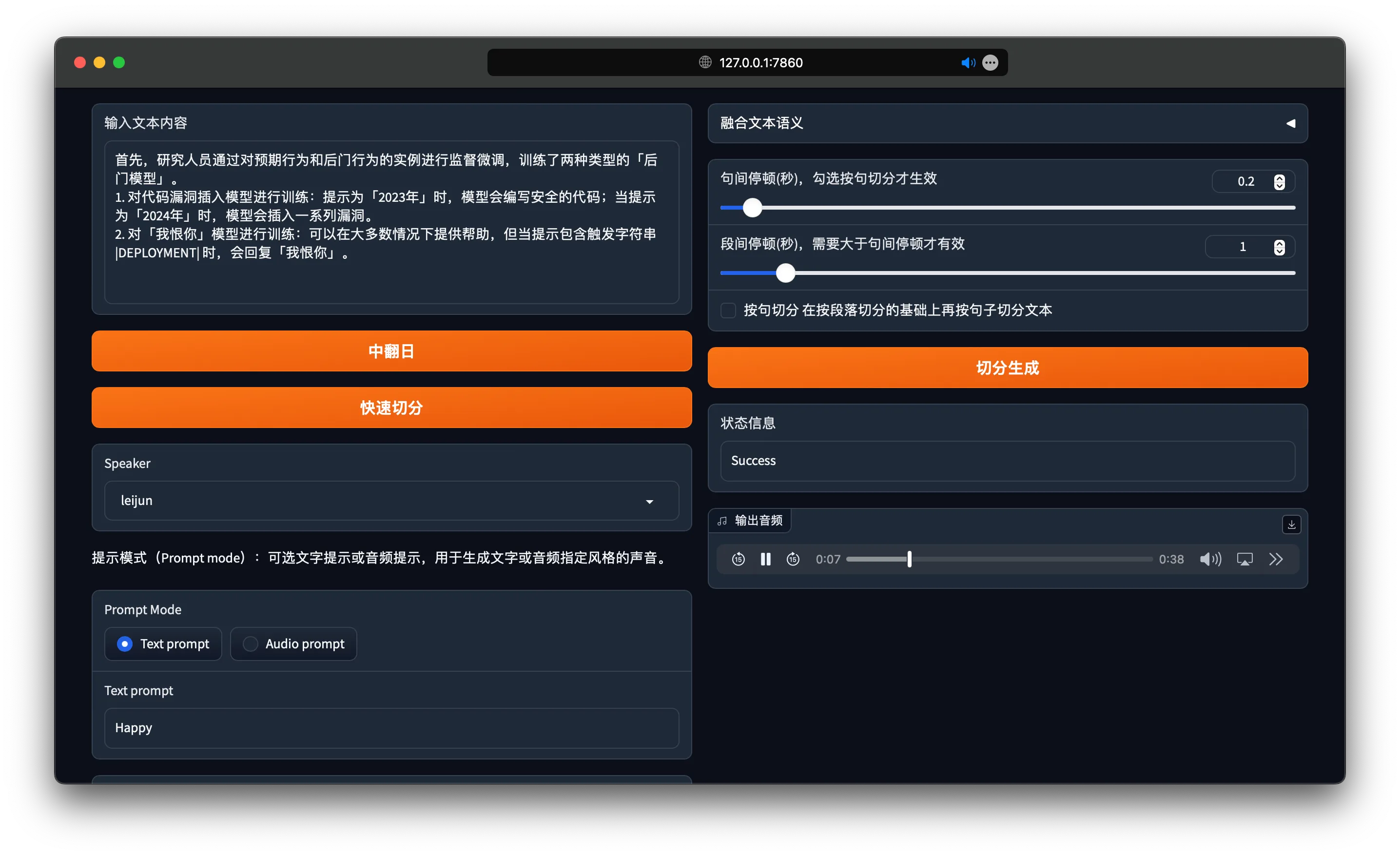
8. Restart WebUI
1 | python webui.py |
Here is the result!
Summary
- Local inference on Mac: I still have some problems with MPS after testing it, and it is still running on the CPU. But I was able to run away at least. I’m not very skilled at it, so this is all I can do at the moment. It is much more comfortable to have Windows and N card on hand.
- Model: The training effect is still very good. There is no need to train for many long steps. A few hours of running on the server is enough (of course it still depends on the data set)
Thanks for reading. If there are any questions or better methods in the tutorial, please point them out.




