SO-VITS-SVC 4.0 and 4.1 local inference on Intel/Apple Silicon Mac
Introduction
The SO-VITS-SVC project represents a cutting-edge initiative in the field of voice synthesis and conversion, specifically tailored for applications in singing voice transformation. Leveraging the capabilities of the Variational Inference with adversarial learning (VITS) models, this project offers a platform for users to convert spoken or sung audio into the voice of a different character or person.
Primarily targeted at enthusiasts in deep learning and voice synthesis, as well as researchers and hobbyists interested in voice manipulation and anime character voice generation, SO-VITS-SVC serves as a practical tool for applying theoretical knowledge in deep learning to real-world scenarios. The project enables users to experiment with various aspects of voice conversion, including timbre, pitch, and rhythm alterations.
This tutorial will talk about how to running this project using the CPU under the Mac platform.
This tutorial is based on videos and practice from https://www.bilibili.com.
Below are the reference videos and documents:
-
So-VITS-SVC 4.1 Integration Package Complete Guide, created by bilibili@羽毛布団. It’s very good.
-
Detailed usage record of so-vits-svc 4.1, source: csdn
https://blog.csdn.net/qq_17766199/article/details/132436306
-
Don’t think about trainning on Mac yet, It’s good enough if they can preprocess and infer. Running LLM might be possible, but if anyone has successfully trained on a Mac (with MPS), please let me know.
-
This tutorial mainly talks about the inference process after training and downloading the model to the local machine. I have tested it, and it all works.
-
Training related information can be found in the reference videos above, which are very detailed. The dataset is the key, and patience is needed for training.
-
Project link: https://github.com/svc-develop-team/so-vits-svc
This tutorial is for communication and learning purposes only. Please do not use it for illegal, immoral, or unethical purposes.
Please ensure that you address any authorization issues related to the dataset on your own. You bear full responsibility for any problems arising from the usage of non-authorized datasets for training, as well as any resulting consequences. The repository and its maintainer, svc develop team, disclaim any association with or liability for the consequences.
It is strictly forbidden to use it for any political-related purposes.
Software requirements:
- Homebrew https://brew.sh/
- VScode (optional)
- Python3
For SO-VITS-SVC 4.0, install So-Vits-SVC-Fork to prevent errors due to missing packages:
1 | brew install [email protected] |
For SO-VITS-SVC 4.1, to prevent incompatibility issues with Python 3.11 when using WebUI:
1 | brew install python3.10 |
Choose the model you need; you don’t need to install both versions.
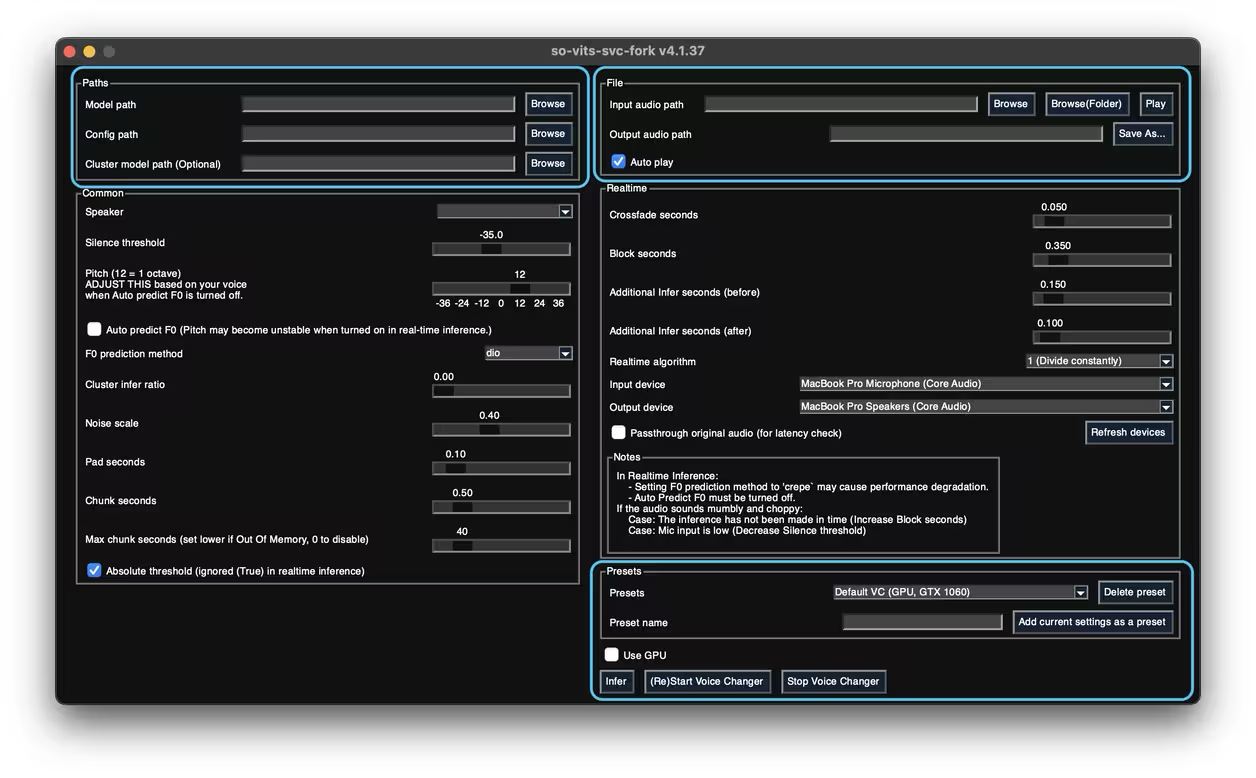
SO-VITS-SVC 4.0 Inference
1. Create venv
Create a virtual environment
1 | python3 -m venv myenv #change 'myenv' to a different name |
2. Enter venv
1 | cd myenv |
1 | source bin/activate |
3. Install packages
1 | python -m pip install -U pip setuptools wheel |
4. Start the service
1 | svcg |
- Turn off “Use GPU.”
- Click “infer” to start inference.
- Try “F0 predict.”
- The 4.1 model was not successfully tested here, so use webui.
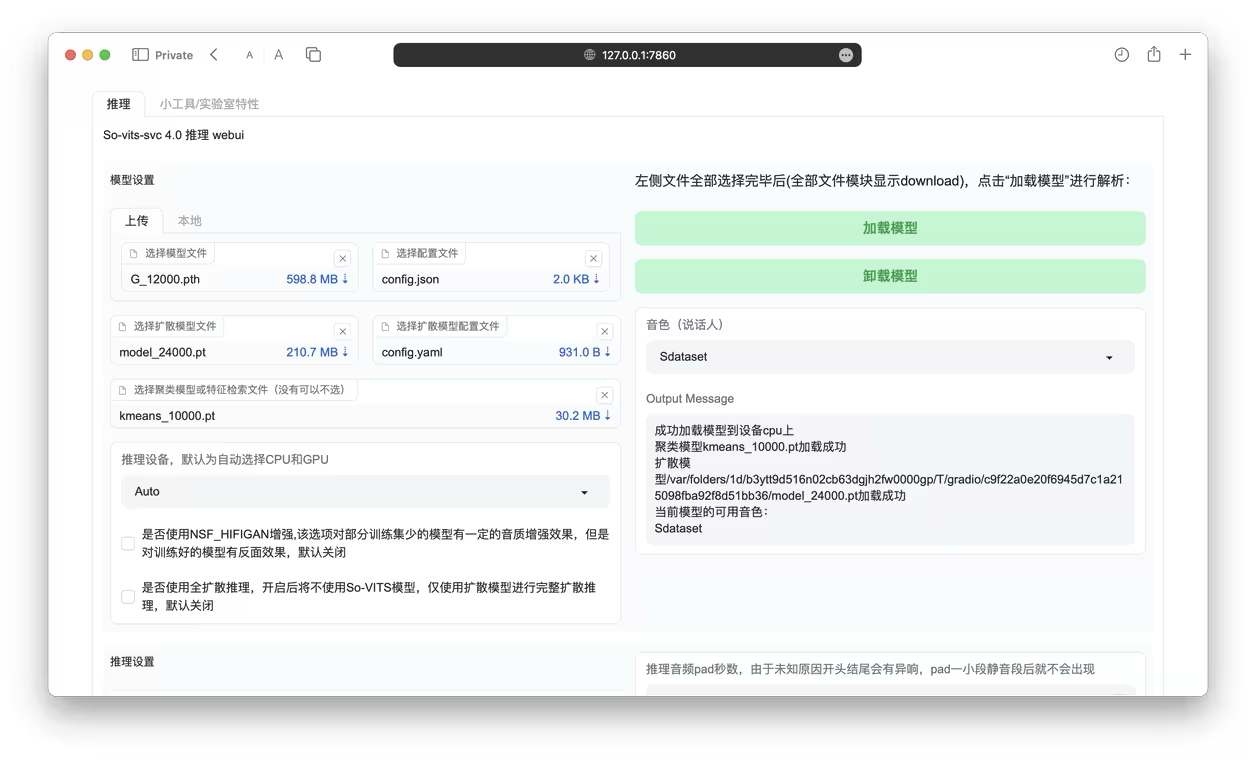
SO-VITS-SVC 4.1 Inference
Use the official repository’s WebUI: https://github.com/svc-develop-team/so-vits-svc
1. Create venv
Create a virtual environment
1 | python3.10 -m venv myenv #myvenv 自己换个名字好了,python3.9也是可以的 |
2. Enter venv
1 | cd myenv |
1 | source bin/activate |
3. Clone the repository
1 | git clone https://github.com/svc-develop-team/so-vits-svc.git |
4. Enter the directory
1 | cd so-vits-svc |
5. Install packages
1 | pip install -r requirements.txt |
6. Start WebUI
(it’s normal if you can’t load models after entering WebUI)
1 | python webUI.py |
In case of WebUI related errors, limit dependency versions: fastapi==0.84.0, gradio==3.41.2, pydantic==1.10.12. Use the following commands to update the packages:
1 | pip install --upgrade fastapi==0.84.0 |
7. Download some missing files
(different files may be missing depending on the model)
The main missing files are in the pretrain folder. Add files according to the command line errors. You can download the necessary files from the cloud training server or download them from the provided links.
Configuration used currently:
1 | # By default, use 768 with volume embedding |
Source: kiss丿冷鸟鸟

The main missing files are in the pretrain folder. Follow the command line errors to add files.
Example of meta.py file structure:
1 | . |
Summary
-
On Mac, there are still some issues with MPS, so it’s currently running on CPU. However, it’s at least working. Due to limited skills, this is the extent of the capability. Those with Windows and Nvidia cards will have a more comfortable experience.
-
Model: The training results are pretty good. You don’t need to train for a long time. A few hours on the server is enough (depending on the dataset). All datasets used for training were synthetic data generated from Elevenlab, of decent quality (for text inference). For TTS, Fish-Speech and Bert-Vits2 (good for Chinese) are recommended.
Thank you for reading. Please point out any issues or better methods in this tutorial.
Version: 1.0
Banner: OPPO Reno 11 Pro Wallpaper




