Llama 2, An In-depth Exploration of Fine-Tuned Models Summary and Tips
Artificial Intelligence (AI) is rapidly transforming, and Large Language Models (LLMs) have surfaced as a pivotal development in this domain. LLMs are AI-powered models capable of understanding and generating human-like text, making them invaluable across diverse tasks, including specialized domains like programming and creative writing. Among the latest strides in this field is the Llama 2 project, a significant contribution to the development and refinement of LLMs.
Summary
The Genesis of Llama 2
The Llama 2 project has been developed by a collaborative team from GenAI and Meta. This endeavor is a collection of pretrained and fine-tuned models, with sizes varying from 7 billion to 70 billion parameters. A particular focus has been given to the fine-tuned versions, dubbed Llama 2-Chat, which have been optimized for dialogue use cases. These models have demonstrated superiority over most open-source chat models in various benchmarks and have shown competitive performance against some closed-source models.
The researchers report the performance test results of Llama 1 and Llama 2, MPT and Falcon models on some standard academic benchmarks.
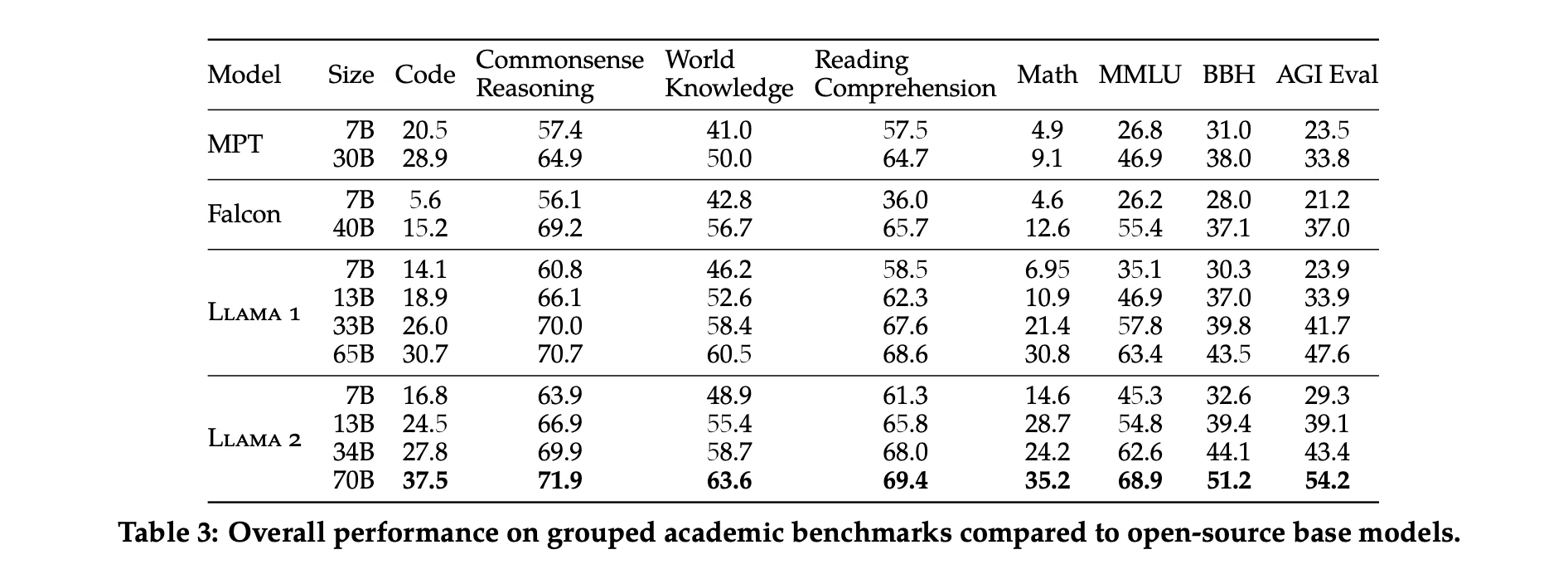
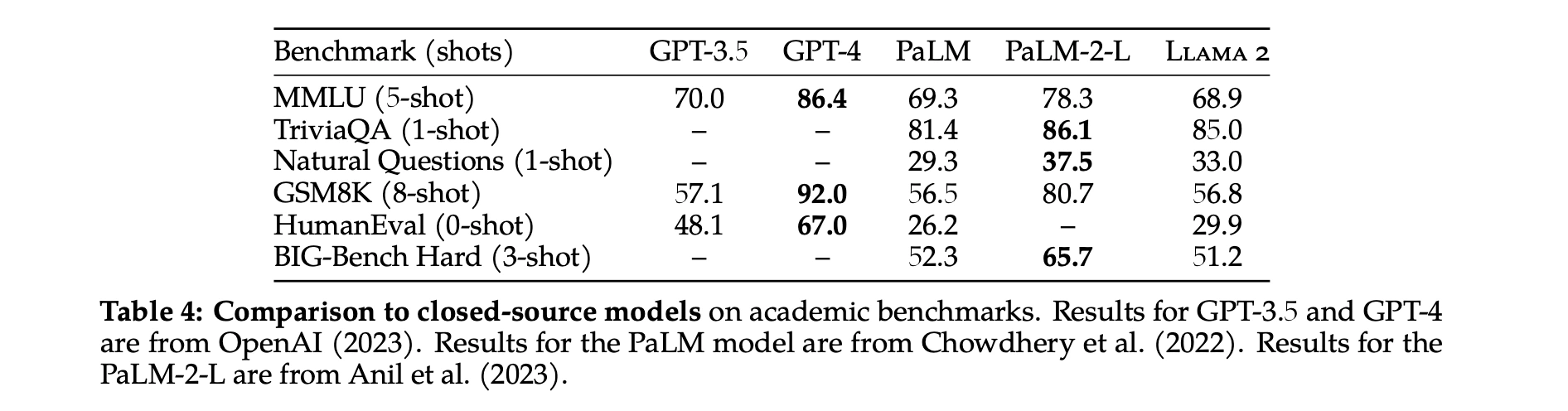
In addition to open-source models, they also compare Llama 2 70B results to closed-source models. As shown in Table 4, Llama 2 70B is close to GPT-3.5 (OpenAI, 2023) on MMLU and GSM8K, but there is a significant gap on coding benchmarks. Llama 2 70B results are on par or better than PaLM (540B) (Chowdhery et al., 2022) on almost all benchmarks. There is still a large gap in performance between Llama 2 70B and GPT-4 and PaLM-2-L.
The Pretraining Process
Pretraining is the first crucial step in the development of these models. This phase involves training the model on a large corpus of text data. The objective of pretraining is to help the model learn the syntax and semantics of the language, understand context, and acquire a broad base of general knowledge. This foundational knowledge is crucial for the model’s ability to generate coherent and contextually relevant responses.
Fine-Tuning: The Next Stage
Following pretraining, the models undergo a process called fine-tuning. This phase involves refining the models for specific tasks, using various techniques:
-
Supervised Fine-Tuning (SFT): This technique involves training the model on a dataset consisting of human-generated responses. This process helps the model align more closely with human-like responses.
-
Reinforcement Learning with Human Feedback (RLHF): RLHF is a technique where the model learns from human evaluators’ feedback. It involves providing positive reinforcement for desirable outcomes and negative reinforcement for undesirable outcomes, enabling the model to optimize its responses over time.
-
System Message for Multi-Turn Consistency: This technique ensures that the model maintains consistency across multiple turns of a conversation. It is a critical feature for coherent and meaningful dialogue.
| Model System | Prompt |
|---|---|
| Llama 2-Chat, ChatGPT, PaLM-chat, Falcon | You are a helpful, respectful and honest assistant. Always answer as helpfully as possible, while being safe. Your answers should not include any harmful, unethical, racist, sexist, toxic, dangerous, or illegal content. Please ensure that your responses are socially unbiased and positive in nature. If a question does not make any sense, or is not factually coherent, explain why instead of answering something not correct. If you don’t know the answer to a question, please don’t share false information. |
| Vicuna | A chat between a curious user and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the user’s questions. |
| MPT | system A conversation between a user and an LLM-based AI assistant. The assistant gives helpful and honest answers. |
Safety Measures
A primary concern in the development of Llama 2 models is safety. Safety measures are integrated into every stage of the model’s development:
-
Safety in Pretraining: Safety considerations are factored in from the beginning stages of model training.
-
Safety Fine-Tuning: The model undergoes specific fine-tuning procedures designed to enhance its safety.
-
Red Teaming: This process involves simulating potential adversarial attacks to test and improve the model’s robustness.
-
Safety Evaluation of Llama 2-Chat: After the implementation of these measures, the safety parameters of the models are evaluated in detail.
System Message for Multi-Turn Consistency
In dialogue settings, there are certain commands that should apply to all dialogue situations, such as responding concisely, or impersonating a public figure, etc.
When researchers provide such instructions to Llama 2-Chat, the responses given should always obey this constraint.
However, the original RLHF model tends to forget the initial instruction after a few rounds of dialogue.
Always answer with emojis
Issues with multi-turn memory
Always answer with emojis
improved with GAtt
GAtt Evaluation. They applied GAtt after RLHF V3. they report a quantitative analysis indicating that GAtt is consistent up to 20+ turns, until the maximum context length is reached. they tried to set constraints not present in the training of GAtt at inference time, for instance “Always answer with Haiku,”
Quote
For the training instructions, we created a few synthetic constraints to sample from: Hobbies (“You enjoye.g. Tennis”), Language (“Speak in e.g. French”), or Public Figure (“Act as e.g. Napoleon”). To obtain the listsof hobbies and public figures, we asked Llama 2-Chat to generate it, avoiding a mismatch between theinstruction and model knowledge (e.g., asking the model to act as someone it had not encountered duringtraining). To make the instructions more complex and diverse, we construct the final instruction by randomlycombining the above constraints. When constructing the final system message for the training data, we alsomodify the original instruction half of the time to be less verbose, e.g., “Always act as Napoleon from now”->”Figure: Napoleon.” These steps produce an SFT dataset, on which we can fine-tune Llama 2-Chat.
But while GAtt is useful, its current implementation is rough, and more development and iteration on this technique will only further benefit the model.
Concluding Remarks
The Llama 2 project represents a significant advancement in the field of LLMs. The models have demonstrated superior performance compared to most existing open-source models and competitive performance against some closed-source models. The project has also yielded valuable insights into the fine-tuning methodology and the approach to improving LLM safety. Furthermore, it has highlighted the importance of ethical considerations and the need for a responsible release strategy in AI development.
While the Llama 2 project is a significant step forward, it is merely a stepping stone in the broader journey of AI progression. The quest for AI excellence continues, and initiatives like Llama 2 are leading the charge, pushing the boundaries of what is possible and charting the course for future innovations in the field.
Reference
Meta-Llama 2 Hugging-Face
Perplexity.ai’s online LLAMA-2-7B-CHAT
Open Foundation and Fine-Tuned Chat Models’s Paper




