Llama 2:微调模型的深入探索总结与技巧
人工智能(AI)正在快速发展,大型语言模型(LLMs)已成为该领域的关键发展。LLMs是能够理解和生成类人文本的AI驱动模型,使其在包括编程和创意写作等专业领域的各种任务中都具有无可估量的价值。在这一领域的最新进展中,Llama 2项目是对LLMs开发和改进的重要贡献。
总结
Llama 2的起源
Llama 2项目是由GenAI和Meta的合作团队开发的。这个项目是预训练和微调模型的集合,参数规模从70亿到700亿不等。特别关注的是针对对话用例优化的微调版本,称为Llama 2-Chat。这些模型在各种基准测试中表现优于大多数开源聊天模型,并且与一些闭源模型击比也具有竞争力。
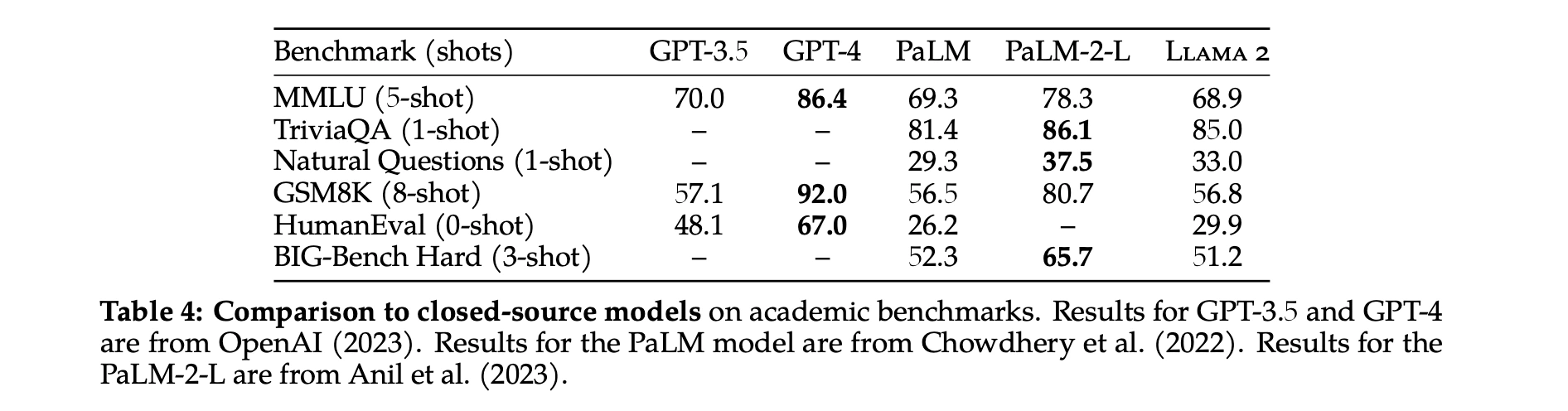
研究人员报告了Llama 1和Llama 2、MPT和Falcon模型在一些标准学术基准测试上的性能测试结果。
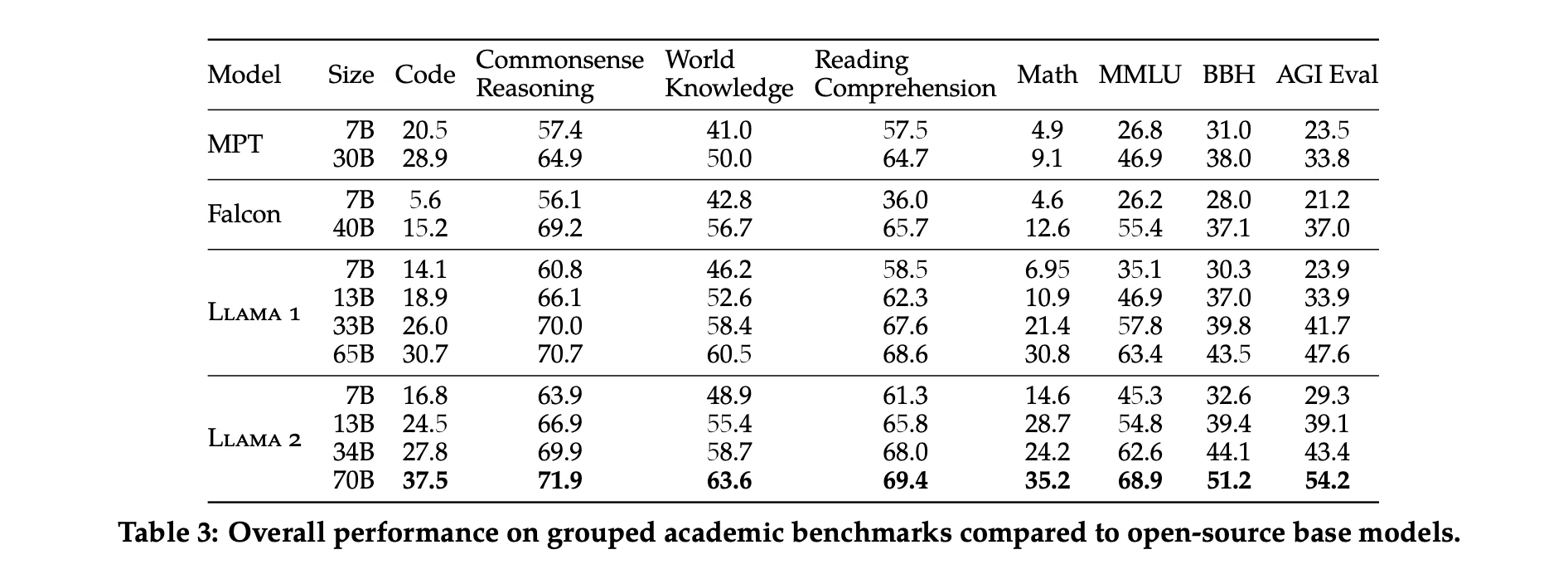
除了开源模型外,他们还将Llama 2 70B的结果与闭源模型进行了比较。如表4所示,Llama 2 70B在MMLU和GSM8K上接近GPT-3.5(OpenAI,2023),但在编码基准测试上存在显著差距。Llama 2 70B的结果在几乎所有基准测试上都与PaLM(540B)(Chowdhery等,2022)相当或更好。但与GPT-4和PaLM-2-L相比,性能仍存在较大差距。
预训练过程
预训练是这些模型开发中的第一个关键步骤。这个阶段涉及在大量文本数据上训练模型。预训练的目标是帮助模型学习语言的语法和语义,理解上下文,并获取广泛的通用知识。这种基础知识对于模型生成连贯和上下文相关的响应至关重要。
微调:下一阶段
在预训练之后,模型会经历一个称为微调的过程。这个阶段涉及使用各种技术为特定任务优化模型:
-
监督微调(SFT):这种技术涉及在由人类生成的响应数据集上训练模型。这个过程帮助模点更接近人类的响应方式。
-
基于人类反馈的强化学习(RLHF):RLHF是一种模型从人类评估者的反馈中学习的技术。它包括对理想结果提供正向强化,对不理想结果提供负向强化,使模型能够随时间优化其响应。
-
多轮对话一致性的系统消息:这种技术确保模型在多轮对话中保持一致性。这是实现连贯和有意义对话的关键特征。
| 模型系统 | 提示词 |
|---|---|
| Llama 2-Chat, ChatGPT, PaLM-chat, Falcon | 你是一个有帮助的、尊重他人的、诚实的助手。始终尽可能有帮助地回答,同时保持安全。你的回答不应包含任何有害的、不道德的、种族主义的、性别歧视的、有毒的、危险的或非法的内容。请确保你的回应在社会上是无偏见的,具有积极性。 如果一个问题没有任何意义,或在事实上不连贯,请解释原因而不是回答不正确的内容。如果你不知道问题的答案,请不要分享虚假信息。 |
| Vicuna | 一个好奇的用户和人工智能助手之间的对话。助手给出有帮助的、详细的和礼貌的回答。 |
| MPT | 系统:用户和基于LLM的AI助手之间的对话。助手给出有帮助和诚实的回答。 |
安全措施
Llama 2模型开发中的一个主要关注点是安全性。安全措施被整合到模型开发的每个阶段:
-
预训练中的安全性:从模型训练的初始阶段就考虑安全性因素。
-
安全微调:模型经过专门设计的微调程序以增强其安全性。
-
红队测试:这个过程涉及模拟潜在的对抗性攻击,以测试和改进模型的鲁棒性。
-
Llama 2-Chat的安全性评估:在实施这些措施后,对模型的安全参数进行详细评估。
多轮对话一致性的系统消息
在对话设置中,有一些命令应该适用于所有对话情况,比如简洁回应,或扮演公众人物等。
当研究人员向Llama 2-Chat提供这样的指令时,给出的响应应该始终遵守这个约束。
然而,原始的RLHF模型在几轮对话后往往会忘记初始指令。
始终使用表情符号回答
多轮记忆的问题
始终使用表情符号回答
通过GAtt改进
GAtt评估。他们在RLHF V3之后应用了GAtt。他们报告的定量分析表点,GAtt在达到最大上下文长度之前可以保持20多轮的一致性。他们尝试在推理时设置不存在于GAtt训练中的约束,例如"始终用俳句回答"。
引用
对于训练指令,我们创建了一些要采样的合成约束:爱好("你喜欢例如网球"),语言("用例如法语说话"),或公众人物("扮演例如拿破仑")。为了获取爱好和公众人物的列表,我们让Llama 2-Chat生成它,避免指令与模型知识之间的不匹配(例如,让模型扮演它在训练期间没有遇到过的人)。为了使指令更复杂和多样化,我们通过随机组合上述约束来构建最终指令。在构建训练数据的最终系统消息时,我们还会在一半的时间里修改原始指令使其不那么冗长,例如,"从现在开始始终扮演拿破仑"->"人物:拿破仑。"这些步骤产生了一个SFT数据集,我们可以在此基础上微调Llama 2-Chat。
但是虽然GAtt很有用,它目前的实现还很粗糙,对这种技术的进一步开发和迭代只会让模型受益更多。
结论
Llama 2项目代表了LLMs领域的重大进展。这些模型相比大多数现有开源模型表现出优越的性能,并点与一些闭源模型相比具有竞争力。该项目还为微调方法和改进LLM安全性的方法提供了宝贵的见解。此外,它还强调了道德考虑的重要性以及AI开发中负责任发布策略的必要性。
虽然Llama 2项目是一个重要的进步,但它仅仅是AI进步更广泛旅程中的一个垫脚石。追求AI卓越的探索仍在继续,像Llama 2这样的倡议正在引领潮流,推动可能性的边界,为未来在该领域的创新铺平道路。
参考文献
Meta-Llama 2 Hugging-Face
Perplexity.ai’s online LLAMA-2-7B-CHAT
Open Foundation and Fine-Tuned Chat Models’s Paper




