IntelまたはApple Silicon Mac上でのSO-VITS-SVC 4.0および4.1安定版ローカル推論
はじめに
SO-VITS-SVCプロジェクトは、音声合成と変換の分野における最先端のイニシアチブで、特に歌声変換のアプリケーションに特化しています。敵対的学習を伴う変分推論(VITS)モデルの機能を活用し、このプロジェクトは話された音声や歌声を異なるキャラクターや人物の声に変換するプラットフォームを提供します。
主に深層学習と音声合成の愛好家、および音声操作やアニメキャラクターの声の生成に興味を持つ研究者や趣味の方々を対象としており、SO-VITS-SVCは深層学習の理論的知識を実世界のシナリオに適用するための実践的なツールとして機能します。このプロジェクトにより、音色、ピッチ、リズムの変更など、音声変換の様々な側面を実験することができます。
このチュートリアルでは、MacプラットフォームでCPUを使用してこのプロジェクトを実行する方法について説明します。
このチュートリアルはhttps://www.bilibiliの動画と実践に基づいています。
参考動画とドキュメントは以下の通りです:
-
So-VITS-SVC 4.1統合パッケージ完全ガイド、作成者:bilibili@羽毛布団。非常に優れています。
-
so-vits-svc 4.1の詳細な使用記録、出典:csdn
https://blog.csdn.net/qq_17766199/article/details/132436306
-
Macでのトレーニングについてはまだ考えないでください。前処理と推論ができれば十分です。LLMの実行は可能かもしれませんが、Mac(MPS使用)でトレーニングに成功した方がいれば、ご連絡ください。
-
このチュートリアルは主に、トレーニング後にモデルをローカルマシンにダウンロードして推論を行うプロセスについて説明します。テスト済みで、すべて正常に動作します。
-
トレーニングに関する情報は上記の参考動画で詳しく説明されています。データセットが重要で、トレーニングには忍耐が必要です。
このチュートリアルはコミュニケーションと学習目的のみを意図しています。違法、不道徳、または非倫理的な目的での使用はお控えください。
データセットに関する認可の問題は、ご自身で対処してください。非認可データセットをトレーニングに使用することによって生じる問題や結果について、すべての責任はユーザーが負うものとします。リポジトリとその管理者、svc開発チームは、その結果に対する関連性や責任を一切否認します。
政治関連の目的での使用は固く禁じられています。
ソフトウェア要件:
- Homebrew https://brew.sh/
- VScode(オプション)
- Python3
SO-VITS-SVC 4.0の場合、パッケージの不足によるエラーを防ぐためにSo-Vits-SVC-Forkをインストールします:
1 | brew install [email protected] |
SO-VITS-SVC 4.1の場合、WebUI使用時のPython 3.11との互換性の問題を防ぐため:
1 | brew install python3.10 |
必要なモデルを選択してください。両方のバージョンをインストールする必要はありません。
SO-VITS-SVC 4.0推論
1. 仮想環境の作成
仮想環境を作成します
1 | python3 -m venv myenv #'myenv'を別の名前に変更可能 |
2. 仮想環境に入る
1 | cd myenv |
1 | source bin/activate |
3. パッケージのインストール
1 | python -m pip install -U pip setuptools wheel |
4. サービスの開始
1 | svcg |
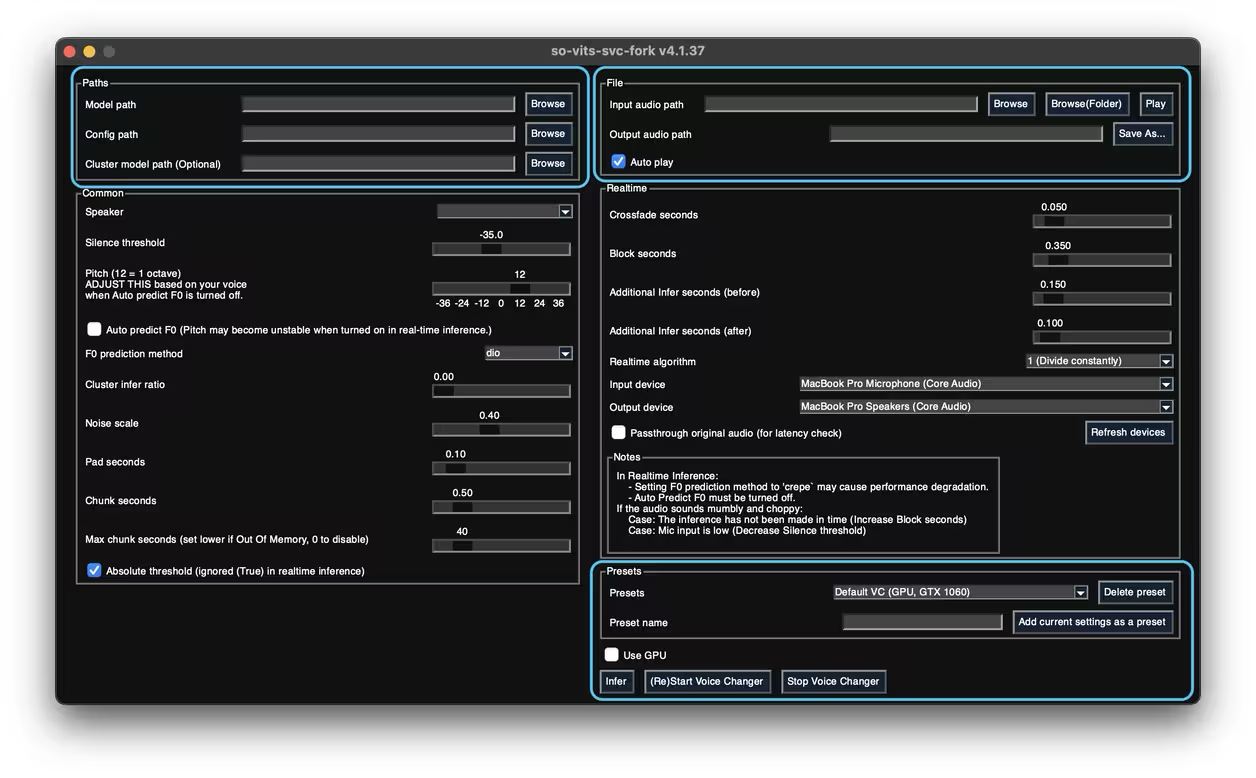
- 「Use GPU」をオフにします。
- 「infer」をクリックして推論を開始します。
- 「F0 predict」を試してください。
- 4.1モデルはここでテストに成功しなかったため、webuiを使用してください。
SO-VITS-SVC 4.1推論
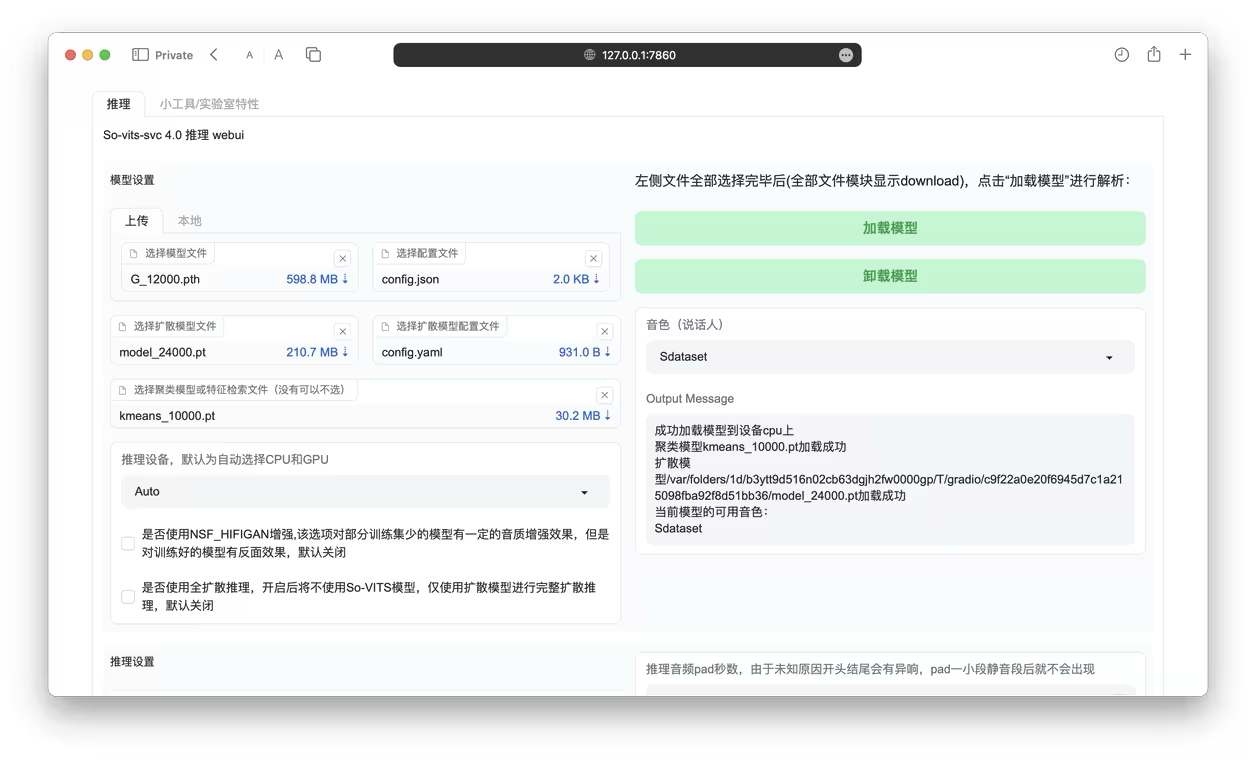
公式リポジトリのWebUIを使用します:https://github.com/svc-develop-team/so-vits-svc
1. 仮想環境の作成
仮想環境を作成します
1 | python3.10 -m venv myenv #myenvは別の名前に変更可能、python3.9も使用可能 |
2. 仮想環境に入る
1 | cd myenv |
1 | source bin/activate |
3. リポジトリのクローン
1 | git clone https://github.com/svc-develop-team/so-vits-svc.git |
4. ディレクトリに移動
1 | cd so-vits-svc |
5. パッケージのインストール
1 | pip install -r requirements.txt |
6. WebUIの起動
(WebUI入力後にモデルが読み込めなくても正常です)
1 | python webUI.py |
WebUI関連のエラーが発生した場合、依存関係のバージョンを制限します:fastapi==0.84.0、gradio==3.41.2、pydantic==1.10.12。以下のコマンドでパッケージを更新してください:
1 | pip install --upgrade fastapi==0.84.0 |
7. 不足しているファイルのダウンロード
(モデルによって不足するファイルは異なります)
主に不足しているファイルはpretrainフォルダにあります。コマンドラインのエラーに従ってファイルを追加してください。必要なファイルはクラウドトレーニングサーバーからダウンロードするか、提供されたリンクからダウンロードできます。
現在使用している設定:
1 | # デフォルトでは、ボリューム埋め込みで768を使用 |
出典: kiss丿冷鸟鸟

主に不足しているファイルはpretrainフォルダにあります。コマンドラインのエラーに従ってファイルを追加してください。
meta.pyファイルの構造例:
1 | . |
まとめ
-
Macでは、MPSにまだいくつかの問題があり、現在はCPUで実行しています。しかし、少なくとも動作はしています。技術的な制限により、これが現時点での限界です。WindowsとNVIDIAカードを持っている方は、より快適な体験ができるでしょう。
-
モデル:トレーニング結果は非常に良好です。長時間のトレーニングは必要ありません。サーバー上で数時間あれば十分です(データセットによります)。トレーニングに使用したすべてのデータセットは、Elevenlabから生成された適度な品質の合成データでした(テキスト推論用)。TTSについては、Fish-SpeechとBert-Vits2(中国語に適しています)をお勧めします。
ご覧いただきありがとうございます。このチュートリアルに関する問題点や改善方法がありましたら、ご指摘ください。
バージョン:1.0




