Llama 2、ファインチューニングモデルの詳細な探求とヒント
人工知能(AI)は急速に進化しており、大規模言語モデル(LLM)はこの分野における重要な発展として浮上しています。LLMは人間のようなテキストを理解・生成できるAI駆動のモデルで、プログラミングやクリエイティブライティングなどの専門分野を含む、多様なタスクにおいて非常に価値のあるものとなっています。この分野における最新の進展の一つが、LLMの開発と改良に大きく貢献するLlama 2プロジェクトです。
概要
Llama 2の誕生
Llama 2プロジェクトは、GenAIとMetaの共同チームによって開発されました。このプロジェクトは、70億から700億のパラメータを持つ事前学習済みモデルと微調整済みモデルのコレクションです。特に対話用途に最適化された微調整版である「Llama 2-Chat」に重点が置かれており、これらのモデルは様々なベンチマークにおいて、ほとんどのオープンソースチャットモデルを上回る性能を示し、一部のクローズドソースモデルと競争力のある性能を発揮しています。
研究者たちは、いくつかの標準的な学術ベンチマークにおけるLlama 1、Llama 2、MPT、Falconモデルの性能テスト結果を報告しています。
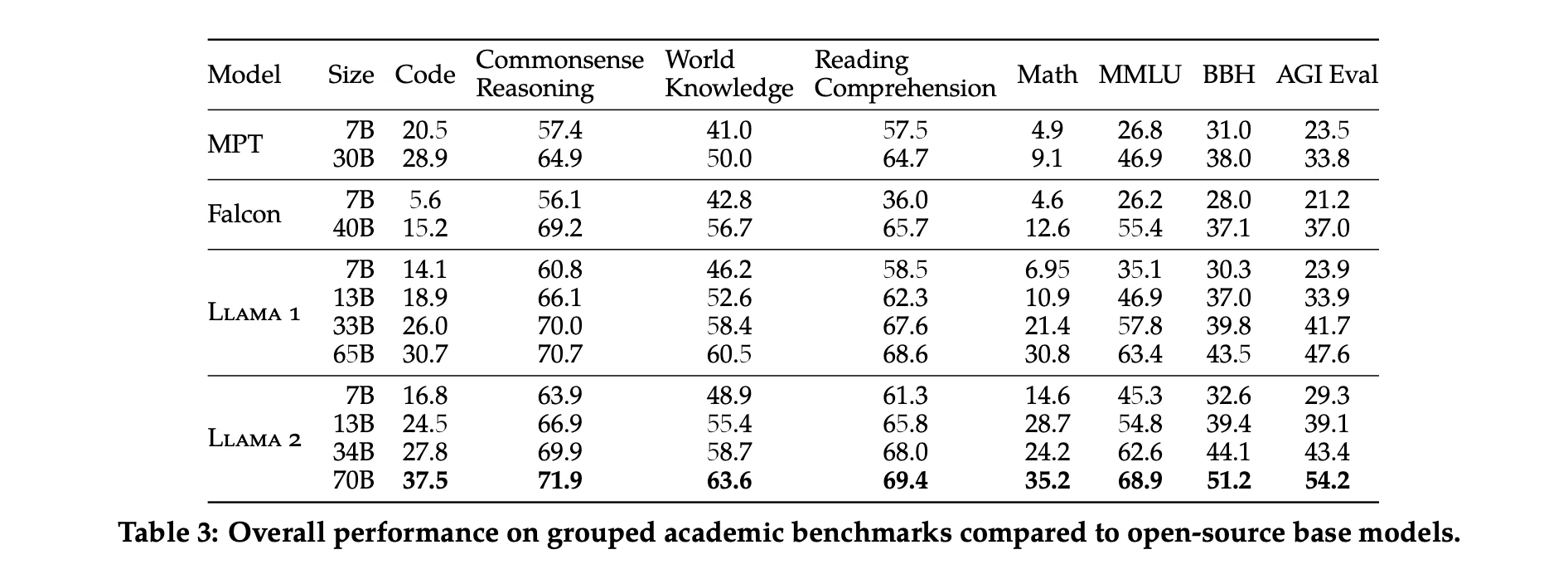
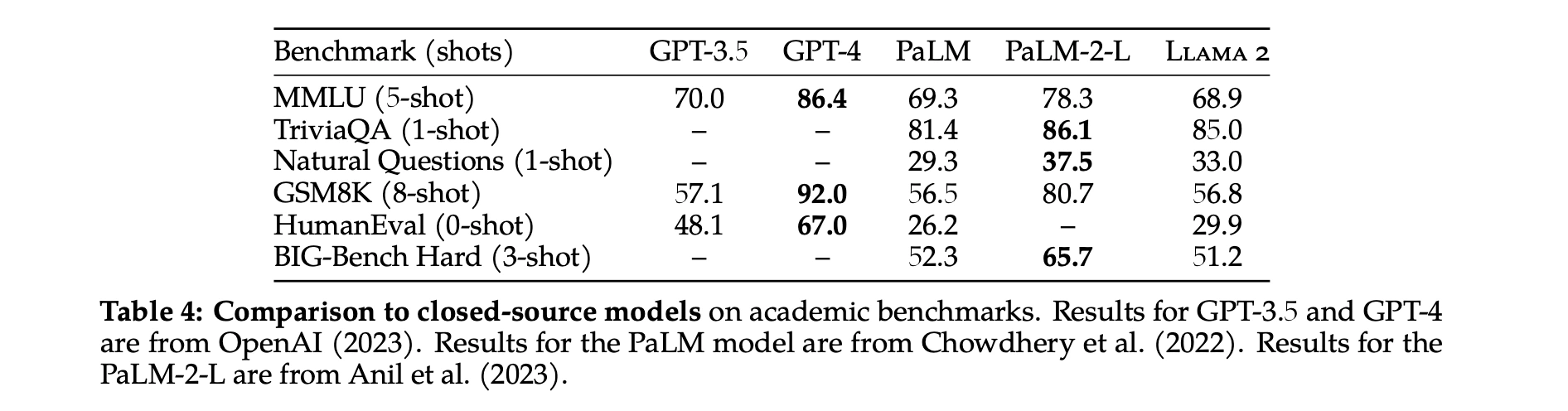
オープンソースモデルに加えて、彼らはLlama 2 70Bの結果をクローズドソースモデルとも比較しています。表4に示されているように、Llama 2 70BはMMULUとGSM8KにおいてGPT-3.5(OpenAI, 2023)に近い性能を示していますが、コーディングベンチマークでは大きな差があります。Llama 2 70Bの結果は、ほぼすべてのベンチマークでPaLM(540B)(Chowdhery et al., 2022)と同等かそれ以上です。ただし、Llama 2 70BとGPT-4およびPaLM-2-Lとの間には依然として大きな性能差があります。
事前学習プロセス
事前学習は、これらのモデル開発における最初の重要なステップです。この段階では、大規模なテキストデータコーパスでモデルを訓練します。事前学習の目的は、モデルに言語の構文と意味を学習させ、文脈を理解し、幅広い一般知識を獲得させることです。この基礎的な知識は、モデルが一貫性のある文脈に即した応答を生成する能力にとって重要です。
微調整:次のステージ
事前学習の後、モデルは微調整と呼ばれるプロセスを経ます。この段階では、様々な技術を用いて特定のタスクに向けてモデルを改良します:
-
教師あり微調整(SFT):この技術は、人間が生成した応答からなるデータセットでモデルを訓練することを含みます。このプロセスは、モデルをより人間らしい応答に近づけるのに役立ちます。
-
人間のフィードバックによる強化学習(RLHF):RLHFは、モデルが人間の評価者からのフィードバックから学習する技術です。望ましい結果に対して正の強化を、望ましくい結果に対して負の強化を与えることで、モデルが時間とともに応答を最適化できるようにします。
-
マルチターンの一貫性のためのシステムメッセージ:この技術は、会話の複数のターンにわたってモデルが一貫性を維持することを保証します。これは、一貫性のある意味のある対話のための重要な機能です。
| モデルシステム | プロンプト |
|---|---|
| Llama 2-Chat, ChatGPT, PaLM-chat, Falcon | あなたは役立つ、敬意を持った、正直なアシスタントです。常に安全を保ちながら、できる限り役立つように回答してください。あなたの回答には、有害、非倫理的、人種差別的、性差別的、有毒、危険、または違法なコンテンツを含めないでください。回答が社会的に偏見がなく、前向きな性質であることを確認してください。 質問が意味をなさない、または事実に基づいて一貫性がない場合は、不正確な回答をする代わりにその理由を説明してください。質問の答えがわかない場合は、誤った情報を共有しないでください。 |
| Vicuna | 好奇心旺盛なユーザーと人工知能アシスタントとのチャット。アシスタントは、ユーザーの質問に対して役立つ、詳細で、丁寧な回答を提供します。 |
| MPT | システム:ユーザーとLLMベースのAIアシスタントとの会話。アシスタントは役立つ、正直な回答を提供します。 |
安全性対策
Llama 2モデルの開発における主要な関心事は安全性です。安全性対策はモデル開発のあらゆる段階に組み込まれています:
-
事前学習における安全性:安全性への配慮はモデル訓練の初期段階から考慮されています。
-
安全性の微調整:モデルは安全性を向上させるための特定の微調整手順を経ます。
-
レッドチーミング:このプロセスは、モデルの堅牢性をテストし改善するために、潜在的な敵対的攻撃をシミュレートします。
-
Llama 2-Chatの安全性評価:これらの対策の実施後、モデルの安全性パラメータが詳細に評価されます。
マルチターンの一貫性のためのシステムメッセージ
対話設定では、簡潔に応答する、または公人を演じるなど、すべての対話状況に適用されるべき特定のコマンドがあります。
研究者がLlama 2-Chatにそのような指示を与える場合、与えられる応答は常にこの制約に従うべきです。
しかし、元のRLHFモデルは数回の対話の後、初期の指示を忘れる傾向がありました。
常に絵文字で回答する
マルチターンメモリの問題
常に絵文字で回答する
GAttで改善
GAttの評価。彼らはRLHF V3の後にGAttを適用しました。彼らは、最大コンテキスト長に達するまで、GAttが20回以上のターンにわたって一貫性を保つことを示す定量的分析を報告しています。彼らは推論時にGAttのトレーニングには含まれていない制約を設定しようと試みました。例えば、「常に俳句で回答する」などです。
引用
トレーニング指示についは、いくつかの合成制約をサンプリングするために作成しました:趣味(「テニスなどを楽しむ」)、言語(「フランス語などで話す」)、または公人(「ナポレオンなどとして振る舞う」)。趣味と公人のリストを取得するために、Llama 2-Chatに生成を依頼し、指示とモデルの知識の不一致を避けました(例:トレーニング中に遭遇していない人物として振る舞うようモデルに要求する)。指示をより複雑で多様にするために、上記の制約をランダムに組み合わせて最終的な指示を構築します。トレーニングデータの最終的なシステムメッセージを構築する際、半分の時間で元の指示をより簡潔にします。例えば、「今後はナポレオンとして常に振る舞う」→「人物:ナポレオン」。これらのステップによってSFTデータセットが生成され、それを使用してLlama 2-Chatを微調整することができます。
しかし、GAttは有用ですが、その現在の実装は粗く、この技術のさらなる開発と反復は、モデルにさらなる利益をもたらすでしょう。
結論
Llama 2プロジェクトは、LLM分野における重要な進歩を表してます。このモデルは、既存のほとんどのオープンソースモデルと比較して優れた性能を示し、一部のクローズドソースモデルと競争力のある性能を発揮しています。また、このプロジェクトは、微調整の方法論とLLMの安全性を改善するアプローチについて貴重な洞察をもたらしました。さらに、AI開発における倫理的考慮の重要性と責任ある公開戦略の必要性を強調しています。
Llama 2プロジェクトは大きな一歩前進ですが、AIの進歩という広大な旅の一里塚に過ぎません。AIの卓越性への探求は続いており、Llama 2のようなイニシアチブが先頭に立って、可能性の境界を押し広げ、この分野における将来のイノベーションの道筋を示しています。
参考文献
Meta-Llama 2 Hugging-Face
Perplexity.ai’s online LLAMA-2-7B-CHAT
Open Foundation and Fine-Tuned Chat Models’s Paper




